In the field of natural language processing, recurrent neural networks (RNN) have shown to produce surprisingly intuitive results with even the most basic architecture. RNNs can be fascinating and spooky at the same time as the output generated from one may give the impression that the neural network holds some semblance of intelligence. When in fact, it is simply a highly effective pattern recognition machine. As a result, a litany of applications using RNNs (from writing Shakespearan plays to creating Dr. Seuss-style rhythmic verses) were spawned to explore, and demonstrate its unreasonable effectiveness.
Here, I will add to the collection of text-generating RNNs with one trained to create news headlines in the style of the Straits Times newspaper from Singapore. You can generate some headlines yourself using the trained network by clicking the Generate Headlines button above. You can also find my source code here.
Headlines Dataset
The raw dataset contains 500,597 URLs from the Straits Times Singapore newspaper site. Like many vendored applications, the Straits Times website (Drupal) follows a standard application stucture and hosts its sitemap file pubicly at https://straitstimes.com/sitemap.xml. From there, it is fairly quick and straightforward to scrape all URLs to form the dataset.
### Please Scrape Responsibly ### from selenium import webdriver from bs4 import BeautifulSoup import time import datetime import re import json # Alter following code to use a different webdriver # Change path to your own chromedriver version driver = webdriver.Chrome('../bin/chromedriver') sitemap_url = "https://www.straitstimes.com/sitemap.xml" driver.get(sitemap_url) sitemap_info = driver.find_elements_by_xpath("//div[@id='information']")[0].text n_pages = int(re.findall(r'\d+', sitemap_info)[0]) today = datetime.datetime.today().strftime("%Y%m%d-%H%M%S") with open('../data/st_sitemap_{}.csv'.format(today), 'w') as f: headers = "url,page" f.write(headers) f.write("\n") for page in list(range(1, n_pages+1)): sitemap_page = sitemap_url+"?page="+str(page) driver.get(sitemap_page) source = driver.page_source anchors = re.findall(r'<td><a href="(.*)" ', driver.page_source) print("Sitemap Page:{}".format(page)) for i, a in enumerate(anchors): row = "{},{}".format(a, str(page)) f.write(row) f.write("\n")
For SEO purposes, most news agencies "slugify" their news article headlines and include them into the URL path. Take for example the news headline:
"New measures to help employers retain maids for a longer period"
The corresponding URL path turns out to be:
/singapore/manpower/new-measures-to-help-employers-retain-maids-for-a-longer-period
Obtaining the headlines dataset is a matter of cleaning the scraped URLs:
import pandas as pd df = pd.read_csv("../data/stsitemap_XXXX.csv") def clean_headline(url): '''Generate headlines from URL ''' headline = url.split('/')[-1] headline = headline.split('-') # Caps first letter of every word headline = [ w[0].upper() + w[1:] if len(w) > 0 else w for w in headline ] headline = ' '.join(headline) return headline def clean_category(url): '''Generate categories from URL ''' category = url.replace('https://www.straitstimes.com/','').split('/')[:-1] # Caps first letter of every word category = [ w[0].upper() + w[1:] if len(w) > 0 else w for w in category ] category = '/'.join(category) return category df['Headline'] = df['url'].apply(lambda x: clean_headline(x)) df['Category'] = df['url'].apply(lambda x: clean_category(x))
| Headline | Category | Wordcount | Charcount |
|---|---|---|---|
| World Briefs Forensic Firm Helping Fbi Unlock Iphone | World | 8 | 52 |
| Colombia Arrests 11 In Sex Trafficking Ring | World/Americas | 7 | 43 |
| Government Protesters Gear Up For Protests With Hong Kong Set To Mark Handover | Asia/East-asia | 13 | 78 |
| Indonesia To Meet Asian Nations Over Maid Welfare | Asia/Se-asia | 8 | 49 |
| Exclusive Titles A Breath Of Fresh Air | Tech/Games-apps | 7 | 38 |
Table 1 - Sample of cleaned dataset
After removing non-headline links and repetitive headlines (i.e., Top News This Week), we get a cleaned dataset ready for some exploratory data analysis. You can access full cleaning code in this notebook.
Exploring the Dataset
We present some summary statistics for the word count and character counts with and without stopwords
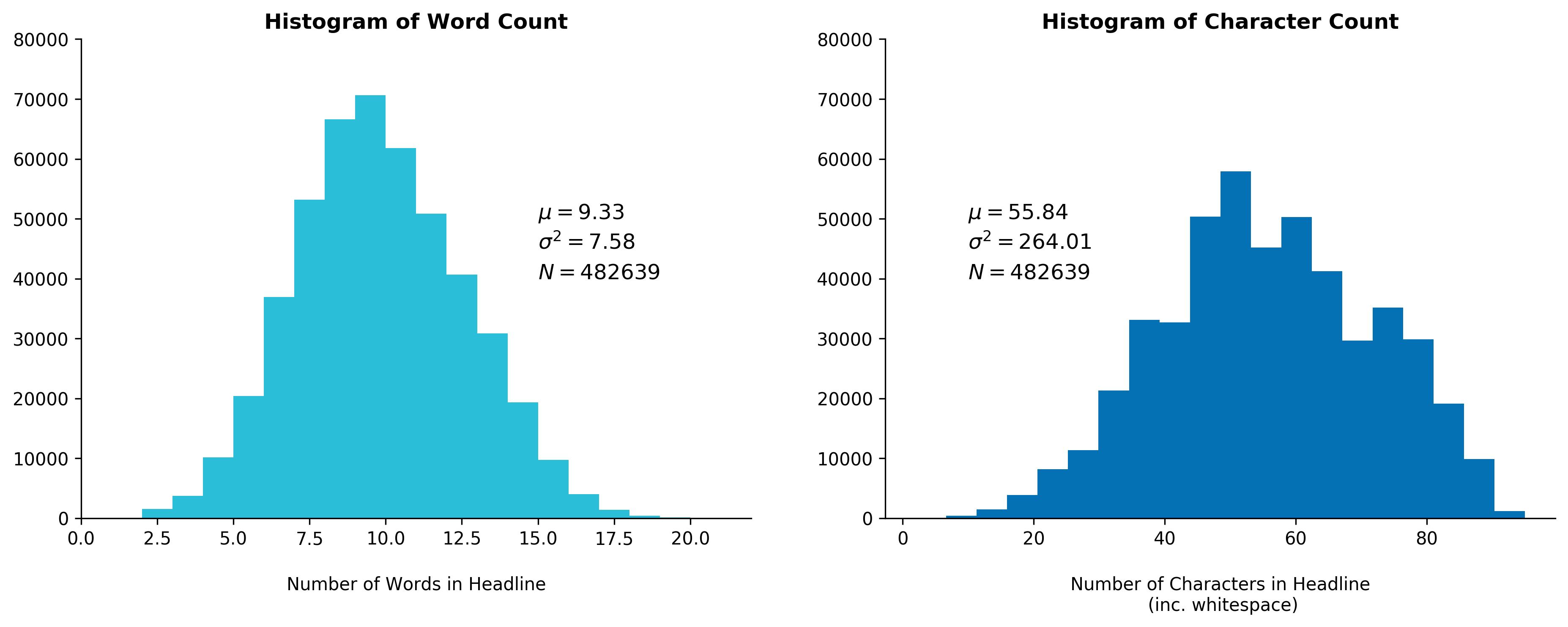
Fig. 1 - Histogram of Word and Character Count
The stopwords corpus is obtained from the nltk library:
import nltk stopwords = set(stopwords.words('english'))
The stopword density in each headline averages to 22 percent, which is on the lower end of the typical 20-30 percent density commonly found in English text. This is unsurprising considering headlines tend to be written in a more condensed manner that packs more information in a shorter sentence. This leaves little room for unneeded stopwords (i.e. pronouns).
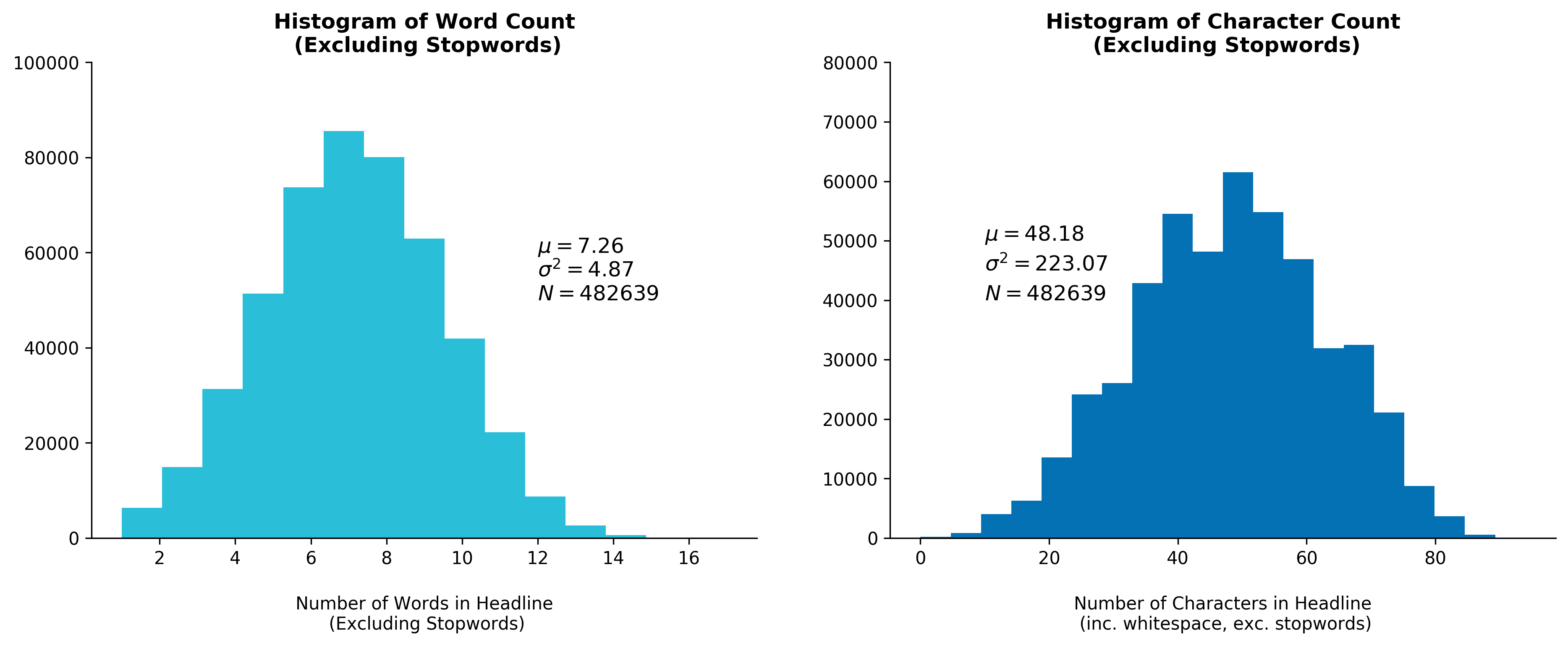
Fig. 2 - Histogram of Word and Character Count
Excluding Stopwords
Exploring the dataset by category, there are a total of 70 categories (including sub-categories) with 'Singapore' news being the largest, taking up 12 percent of all articles.
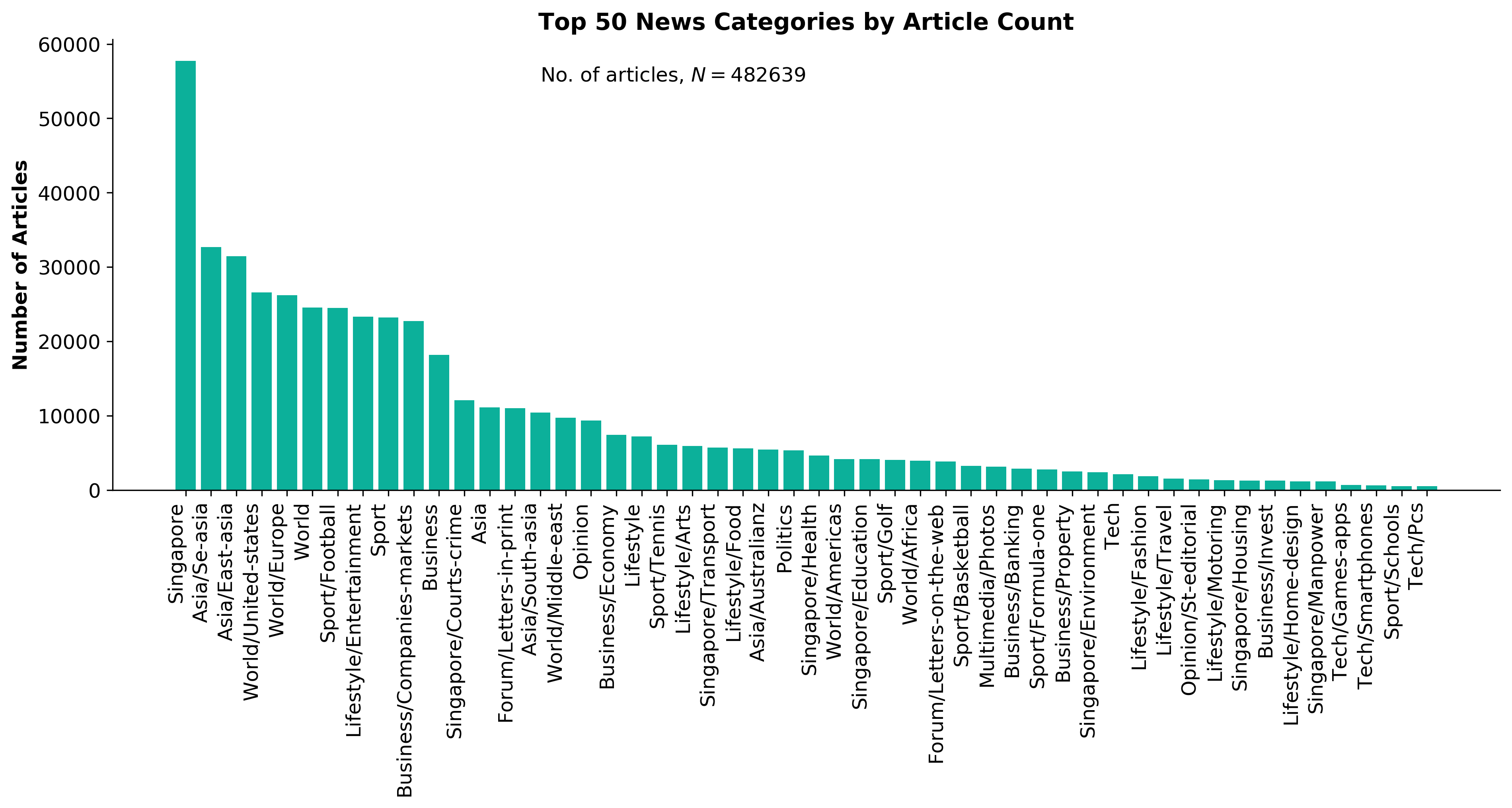
Fig. 3 - Straits Times news categories by article count
Diving into each category, we look at what are the most common words that characterizes the top 25 news segments. Click the sub-category titles below to see the corresponding word cloud.
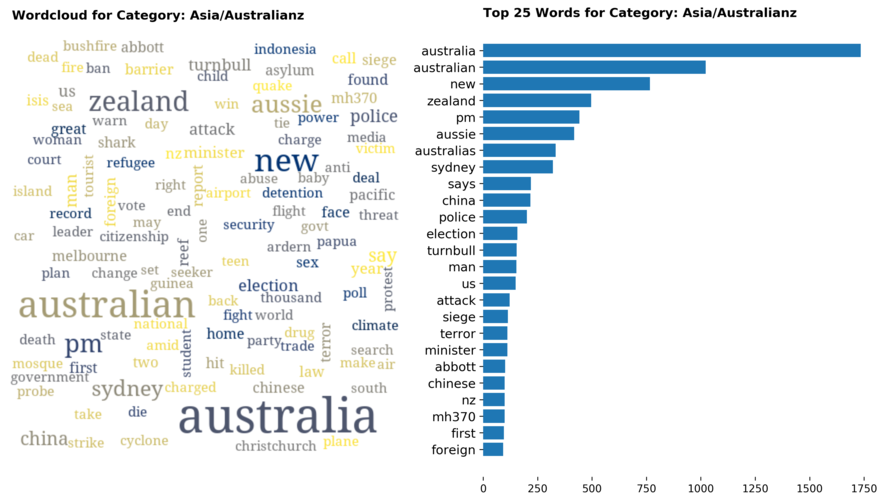
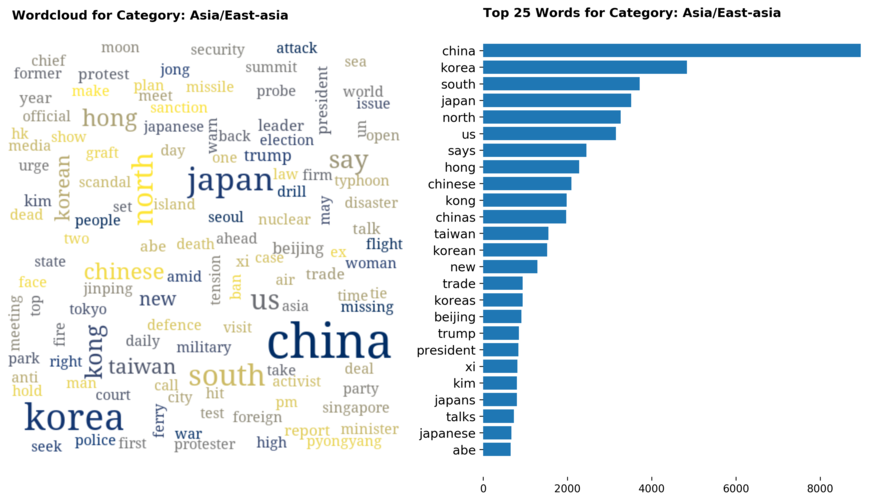
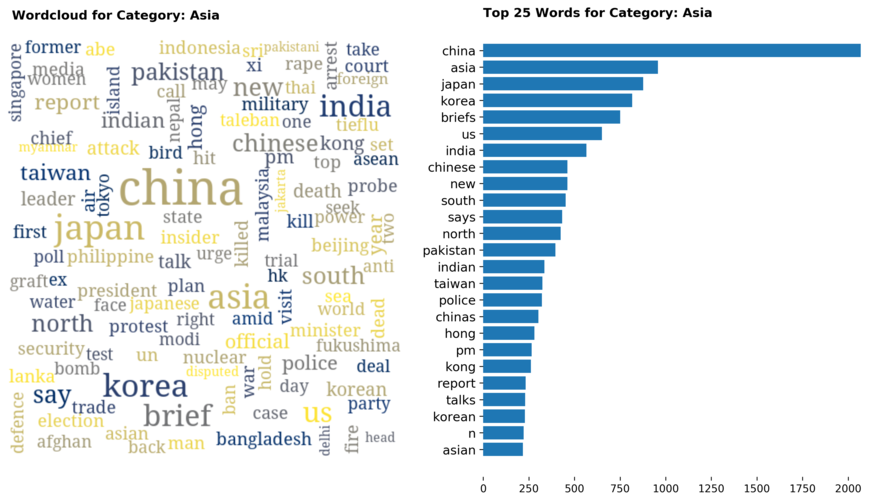
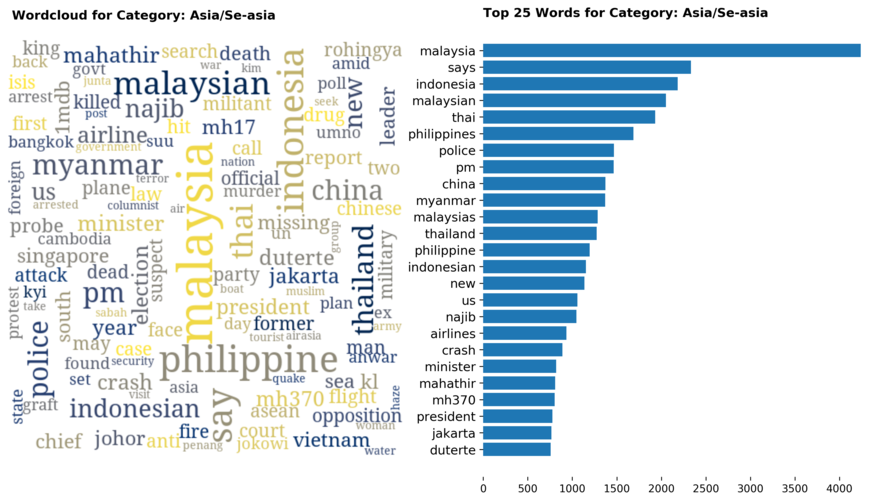
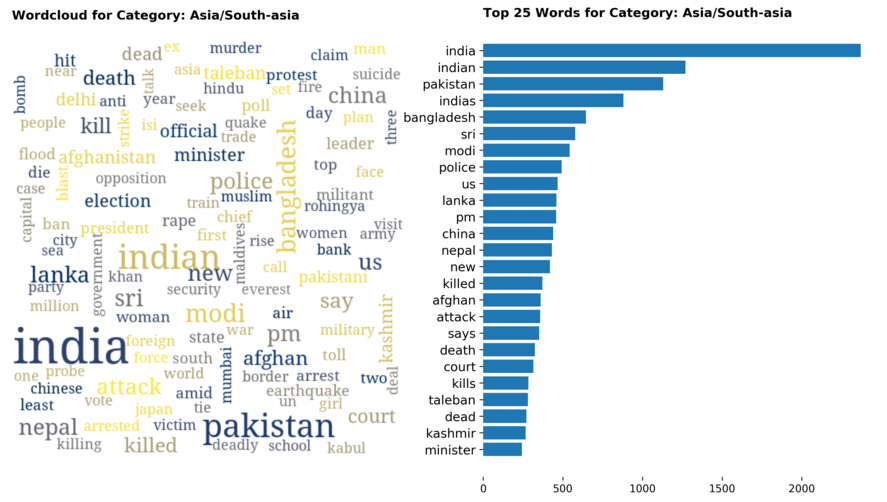
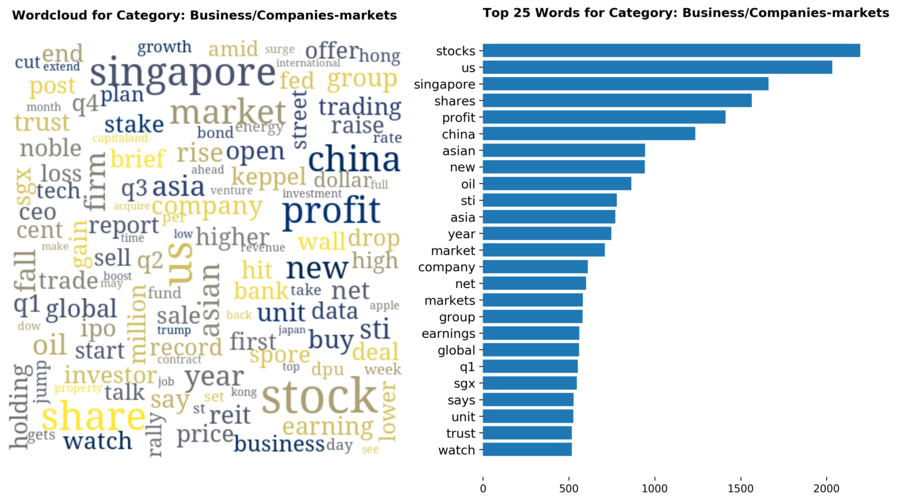
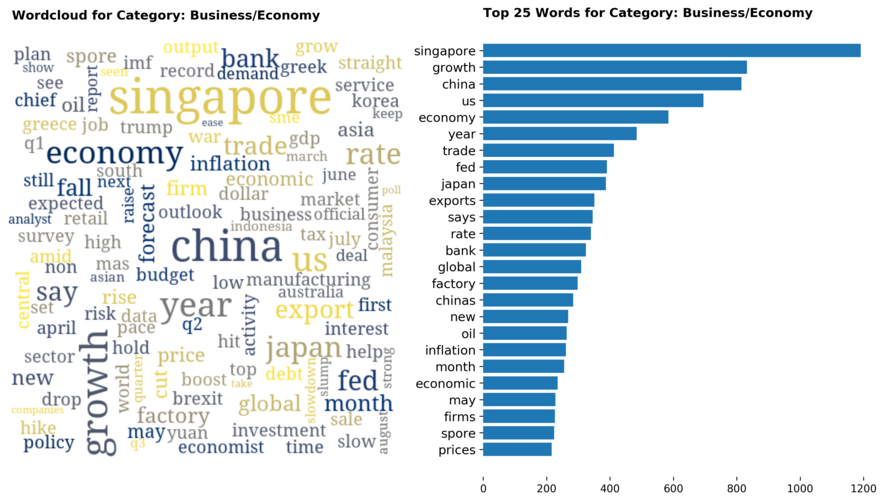
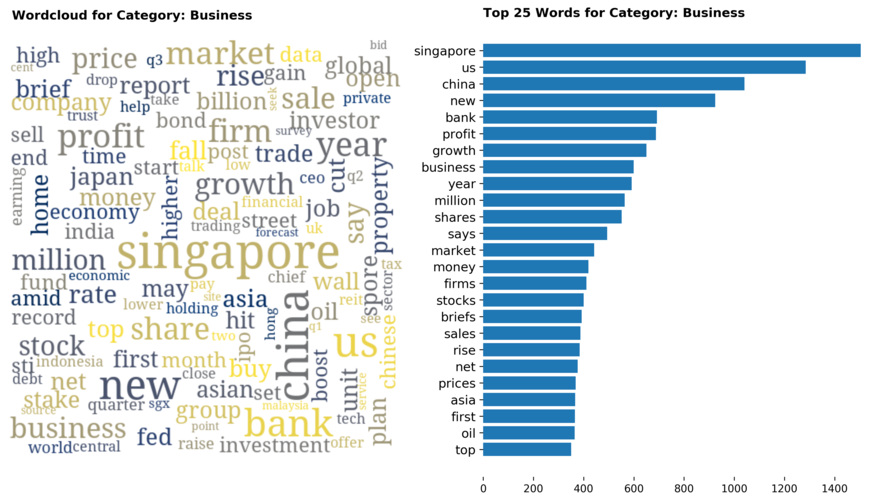
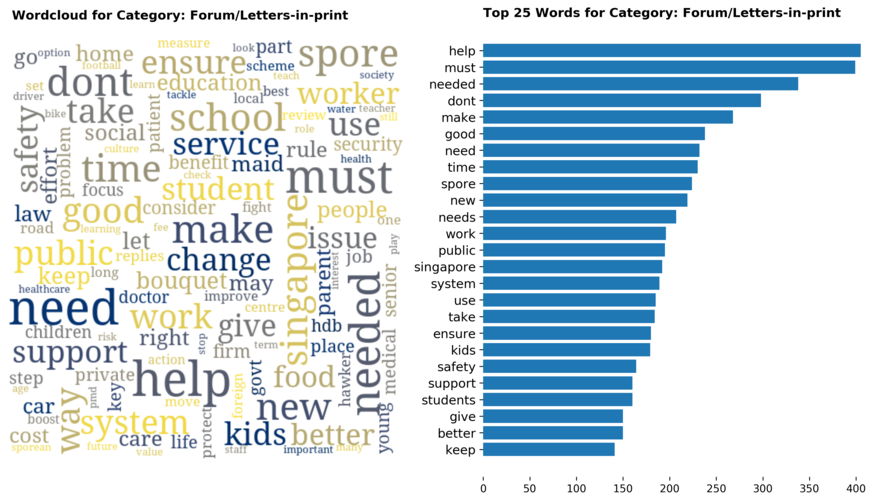
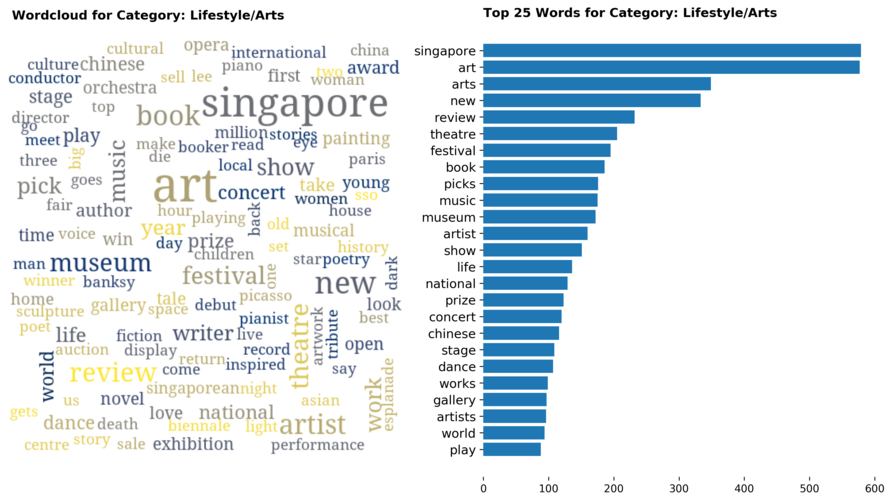
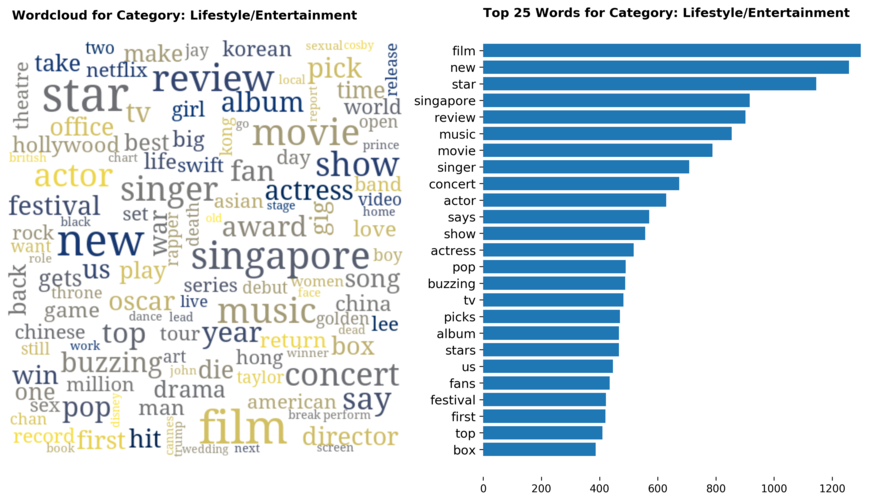
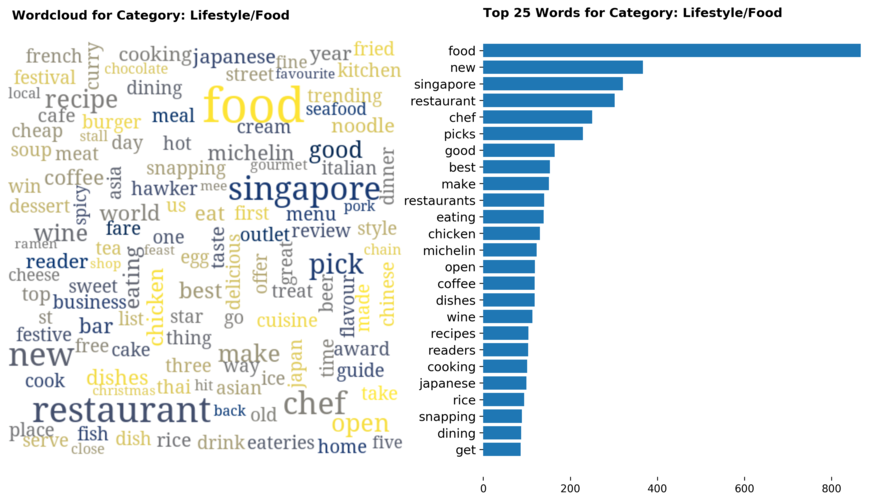
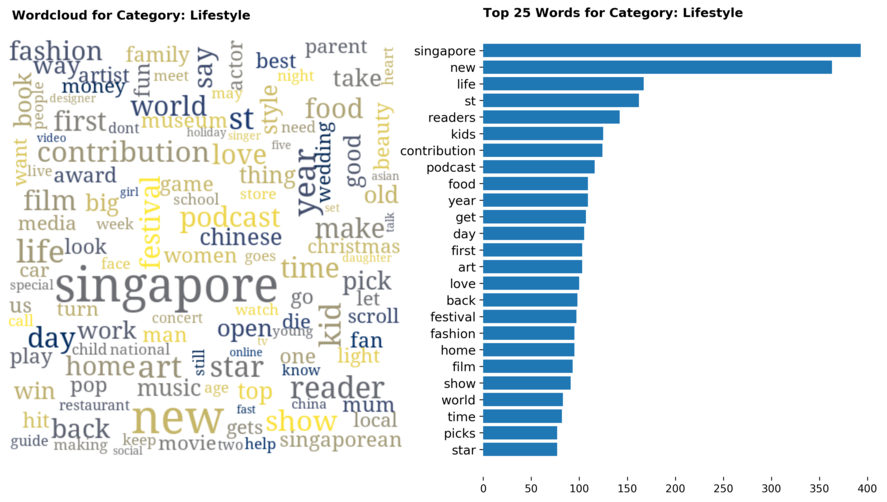
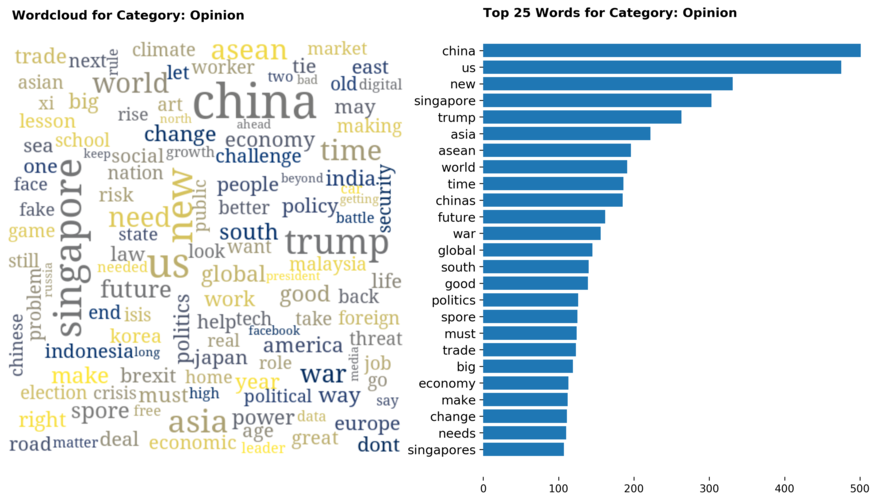
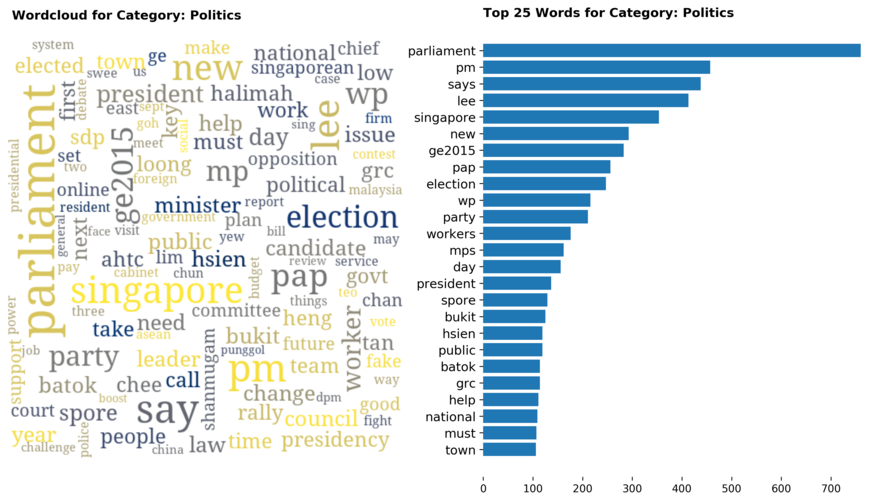
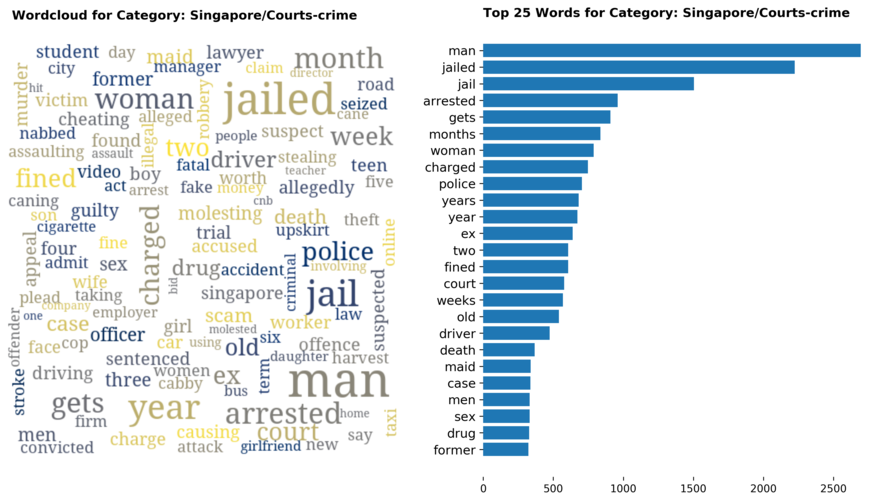
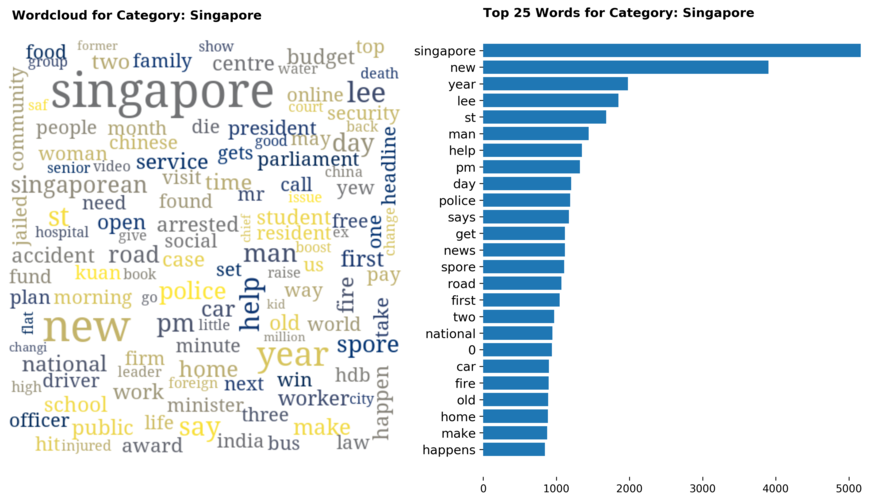
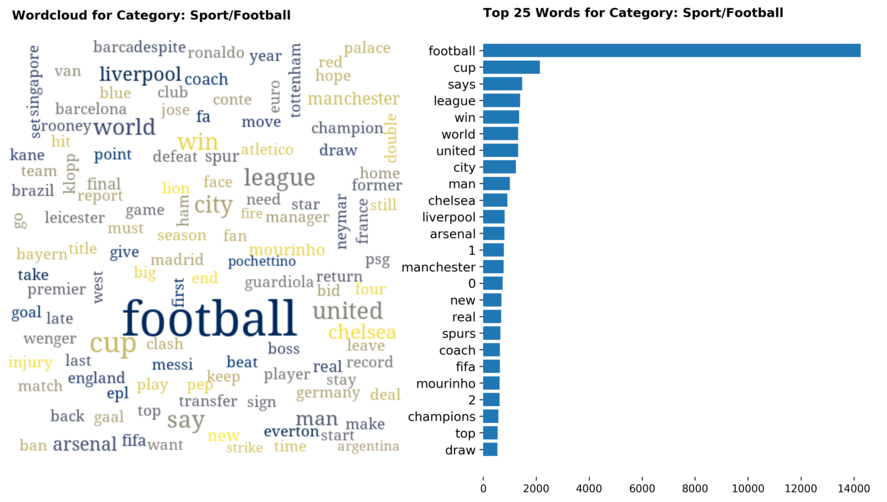
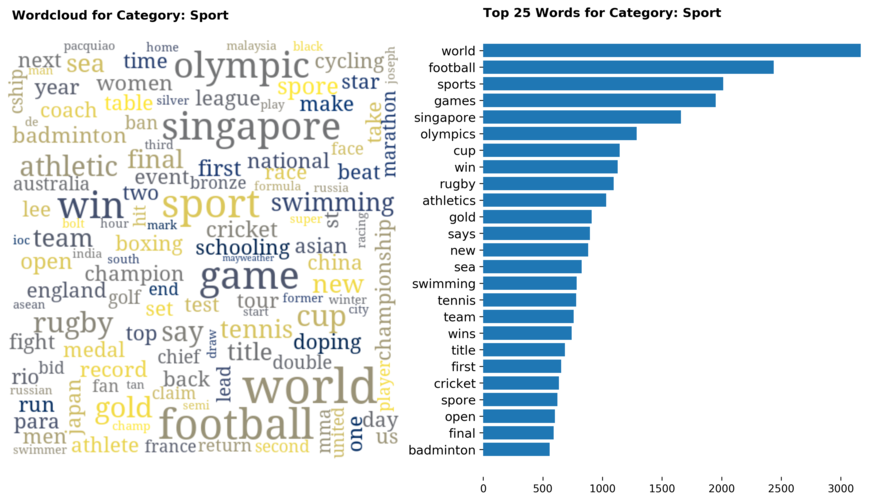
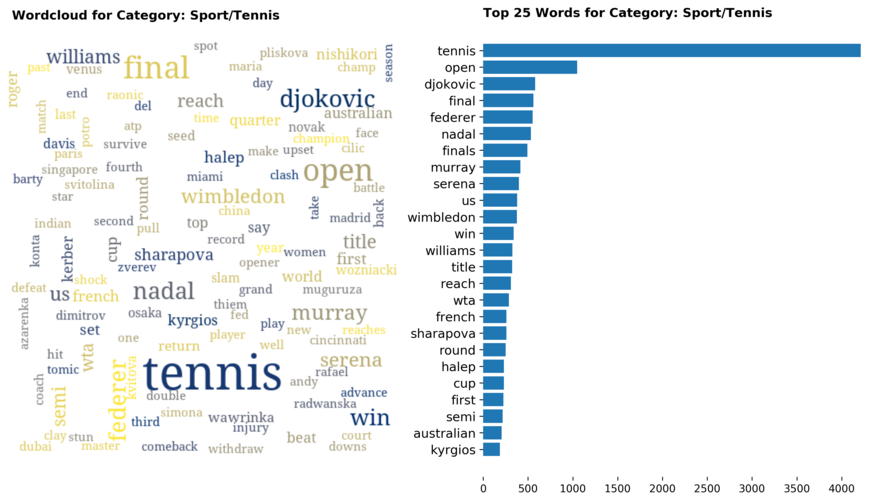
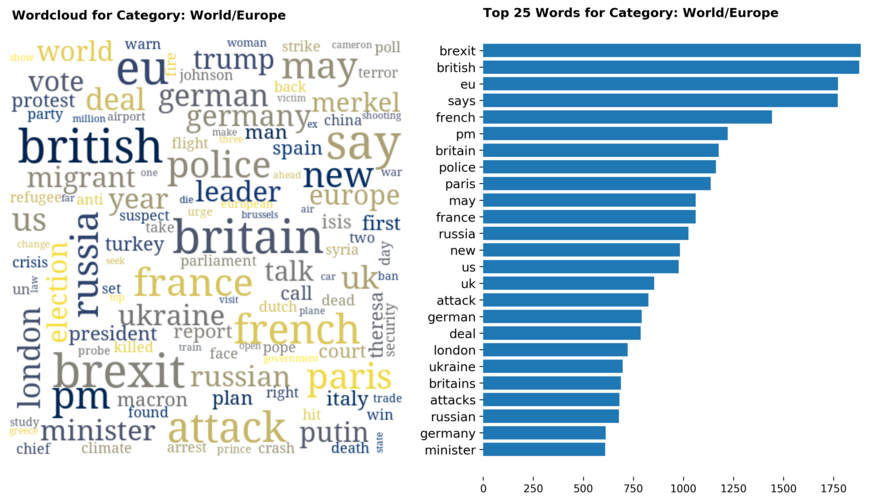
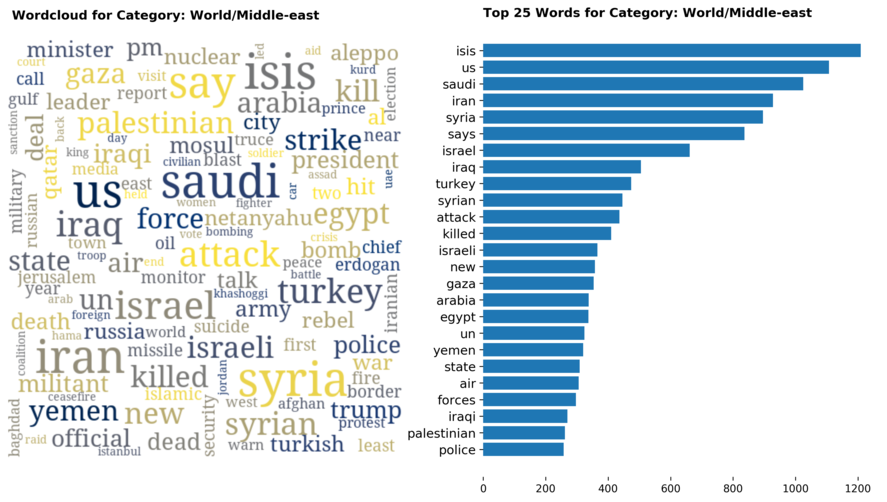
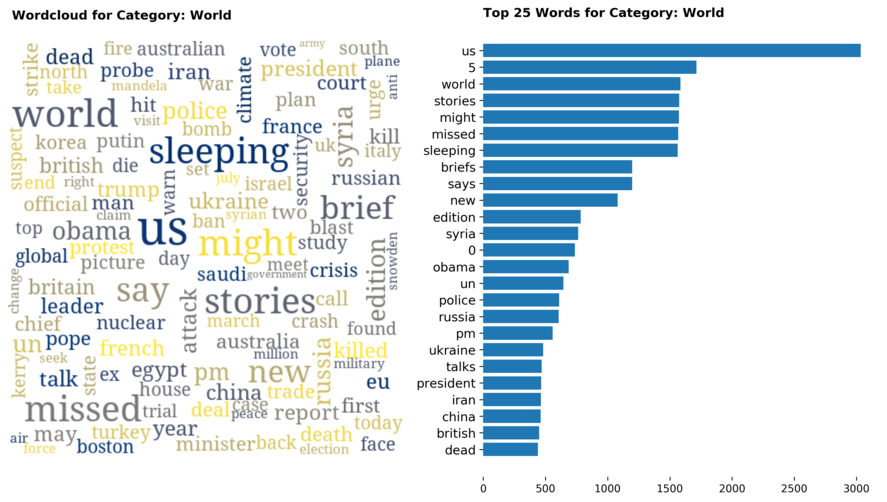
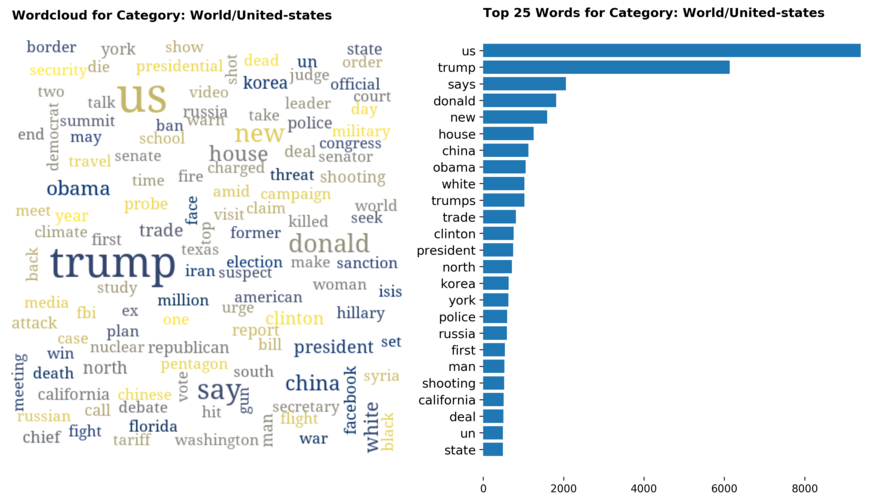
Fig. 3 - Most common words in headlines, by category
While most top keywords in the categories are quite predictable, one interesting finding would be that the most common word for the crime news segment turns out to be man. It is more than twice as likely to appear as compared to the word woman. How would this finding look like juxtaposed against official reported crime rates by gender in Singapore?
Details and code for the exploratory data analysis and wordclouds can be found in this notebook.
Training
For this particular version of the model deployed on this page, I used a simple RNN architecture - single gated recurrent unit (GRU) hidden layer with 1024 nodes. This is trained on a C5.large CPU instance across 3 epochs. For faster results, you can train using a GPU and replace the GRU layer with a CuDnnGRU layer. Using a p2.xlarge instance (AWS Deep Learning AMI) for GPU training, the overall training time took around an hour. A 2-layer CuDnnGRU network across 10 epochs would give better results (i.e. less grammatical mistakes).
def build_model(vocab_size, embedding_dim, rnn_units, batch_size): ''' Wrapper function to build keras TF RNN model. Parameters ---------- vocab_size : int Character-level training. vocab_size refers to the number of unique characters found in training text. embedding_dim : int Output dimension of dense vector for embedding layer rnn_units : int Dimensionality of output space batch_size : int Batch size, # of samples processed before model is updated Returns ------- obj Returns a tensorflow model object ''' model = tf.keras.Sequential([ tf.keras.layers.Embedding( vocab_size, embedding_dim, batch_input_shape=[batch_size, None] ), tf.keras.layers.GRU( units=rnn_units, return_sequences=True, recurrent_initializer='glorot_uniform', stateful=True, recurrent_activation='sigmoid', ), tf.keras.layers.Dense(vocab_size) ]) return model model = build_model( vocab_size = len(words), embedding_dim=256, rnn_units=1024, batch_size=64 ) model.compile( optimizer = tf.train.AdamOptimizer(), loss = loss )
Despite having trained a more powerful network, the simpler CPU-trained model was deployed instead due to cost reasons. As I have recently discovered, to deploy a GPU-trained model, you'd need to use a GPU instance. In other words, you can't make predictions using GRU layers when the model is trained on CuDDnnGU layers (at least not without a great deal of hacking). Also, to speed up predictions so users don't have to wait too long to generate headlines, a single layer model was used. You can view the full training code here.
Some Thoughts
This has been an amusing exercise and the headlines generated have been pretty entertaining. Despite its simple architecture, the RNN did not disappoint in producing some genuinely intuitive and sometimes humourous results ("Obama Calls For Brexit"). However, it seems that beyond that, there is little more the vanilla RNN can do with this dataset. Training at higher epochs, or with added hidden layers only improves its grammar. And of course, while there are no expectations that this network can generate any meaningful headlines, its uncanny ability to mimick what might be considered meaningful will continue to fascinate me.